






The AI community has seen powerful language-vision models like CLIP, DALL-E, FLORENCE, Turing Bletchley, ALIGN, and BASIC.
These AI models can adapt to new datasets without specific labels, but the challenge has been the scarcity of large scale image-text pair training dataset, until now.
In this article, we will introduce you to:
1. LAION-5B — The Open Large-Scale Image-Text Pairs Dataset
2. Three main Challenges of Open Datasets From The Internet
3. Image-Text Pairs Dataset for Commercial Multimodal Large Language Models
1. LAION-5B — The Open Large-Scale Image-Text Pairs Dataset
Introducing LAION 5B, an open-source collection of 5.85 billion high-quality image-text pairs with exploration and training tools, powering DALL-E architecture and advancing multi-modal language-vision model research for a wide community.

LAION-5B's Three Subsets include:
- 2.32 billion English image-text pairs. This subset is referred to as LAION-2B-en or LAION-2B if the language is clear from context.
- 2.26 billion image-text pairs from over 100 other languages. In the multilingual subset, the top-5 most frequent languages are Russian (10.6%), French (7.4%), German (6.6%), Spanish (6.6%), and Chinese (6.3%).
- 1.27 billion samples with undetectable language, often showing products or places. Inspection reveals captions with meaningful language but possibly mixed with SEO keywords or product tags.
The diversity and complexity of the data included in LAION-5B, such as data overlap, image noise, and screening of inappropriate images, allows for a deeper study of the role of low-resource languages and natural languages in multimodal applications while also revealing potential model biases.
It supports:
- Multimodal Pre-training and Image Matching: Improving image embedding models like CLIP for improved image retrieval and zero-shot classification.
- 1.27 billion samples with undetectable language, often showing products or places. Inspection reveals captions with meaningful language but possibly mixed with SEO keywords or product tags.
- Image Generation: Facilitates high-resolution and text-based image generation using subsets for models such as Stable Diffusion and Imagen, resulting in high-quality and creative output.
- Text Generation: Support for image-to-text, visual question answering (VQA), and visual entailment tasks to improve the performance of language models in VQA.
- Classification and Recognition Tasks: Useful for zero-shot learning or fine-tuning in the development of recognition and classification models.
However, when using LAION-5B for industrial problems, be cautious, as unscreened images with watermarks or inappropriate content could bias model training.


2. Three main Challenges of Open Datasets From The Internet
First, LAION-5B's open data highlights the escalating problem of poor-quality data on the internet.
The diverse and variable quality of internet data poses challenges for Generative AI technologies like MLLM, GPT training and application, as low-quality data can result in biased or misleading outcomes, impacting model performance and reliability.
Secondly, the rise of copyright concerns over internet data, much of which is copyrighted, is alarming. Unauthorized use could lead to legal disputes, a critical concern for data-dependent AI models.
Last, internet data consumption is rising due to the growing demands of advanced models like MLLM and GPT, leading to a shortage as data usage outstrips the pace of data creation.
3. Image-Text Pairs Dataset for Commercial Multimodal Large Language Models
maadaa.ai is committed to providing "Data-Centric" professional Generative AI data services and building large-scale high-quality dataset products for the development of Generative AI large language models (LLMs).
Recently, maadaa has officially launched the MLLM (Multimodal Language Model) training dataset: the mGenAI Image-Text Pairs Dataset. This dataset is specially developed for state-of-the-art multi-modal large language models, including various structured datasets like image-text pairs, video-text pairs and e-books in markdown.
Following the rules of international copyright authorization, this large dataset ensures the infusion of authenticity and diversity into Generative AI model training, propelling Generative AI models towards unprecedented accuracy and innovation.
It contains over 300 million graphic-text pairs covering a wide range of high-resolution professional photographic images, including people, animals, landscapes, photographic artwork, vector images, etc.
The following is a comparison of maadaa's mGenAI Image-Text Pairs Dataset and laion5b data set and other MLLM training datasets

And now maadaa has released a FREE sample to download, click below and download maadaa's MLLM Dataset NOW!

Here are some sample images in this mGenAI-Image-Text Pairs Datasets:

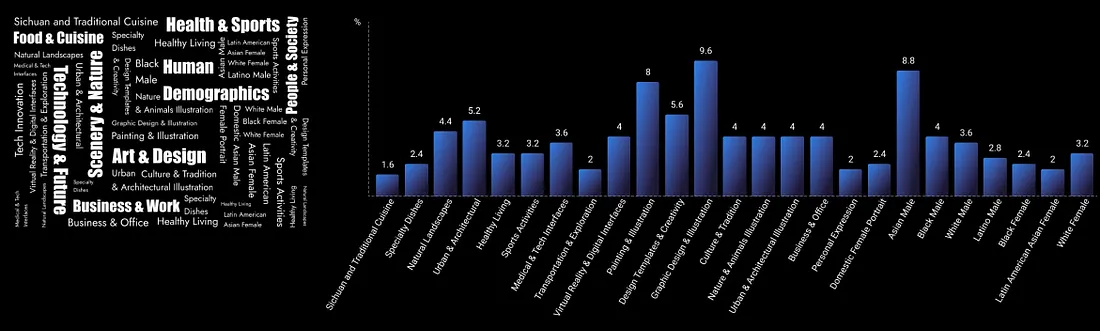
Here is the statistics of this dataset:

Citation:
